作为测试架构师我如何选择团队的虚拟化方案
条评论引语
本文介绍测试团队虚拟化方案设计和实现过程,为什么选择该方案,该方案的优势和劣势,以及后续的实施计划等
实现目标
选择虚拟化方案时,需要考虑以下因素
- 替代现有测试环境,满足将来的团队成长和测试需求
- 完全隔离,消除环境混用带来的环境破坏
- 不会引入违反信创要求的商业风险
- 能够兼容现有的和采购中的体系结构平台,以及需要支持的国产操作系统平台
- 部署和运维难度,成本可控,这里的成本主要指人力成本
- 生产的虚拟环境方便管理和扩展,性能和可用性足够稳定
下面会基于以上需求分析和陈述选型过程中的决策和最终方案
方案调研
选择自己做虚拟化方案已经天然解决了第1点和第2点目标,主要需要从后面4点考虑,即商业风险,兼容性,管理,运维成本
OpenStack
OpenStack是非常成熟和庞大的公有云开源方案,也是第一个调研对象,毫无疑问OpenStack从功能上可以支持所有测试管理需求,甚至多出了很多团队不需要的大型特性,是否多就一定是好呢,答案是未必
参考官方文档和博客,借用packstack和puppet等自动化工具,我花了一周时间才部署出一个allinone的OpenStack环境,以及2个独立的计算节点,调通了一个虚机的生产过程,这个过程中我遇到了类似以下问题
controller node的部署过程中我需要持续不断的输入密码- 由于部署
controller node的虚机hostname带有数字,rabbitmq无法启动 - 由于Linux安全策略,web页面因为不能监听特定端口而无法启动
- 前一次安装失败之后,由于存在失败安装的残留数据本次部署会因为密码错误而无法启动
nova-compute因为访问controller的rabbitmq出错而无法启动- 计算节点的操作系统只支持
OpenStack Rocky,版本滞后OpenStack Train过大而不得不升级操作系统 - 升级后的操作系统因为未适配
OVN controller而无法安装neutron网络agent - …
我不得不查询systemctl status, journal -xe和系统日志去寻找每个出问题涉及模块的蛛丝马迹,以及在不同机器的不同模块日志之间来回跳跃跟踪失败请求,分析和尝试,去完成整个定位和调试过程
直到我们开始复盘整个搭建过程和我们的虚拟化需求,为了利用OpenStack提供的强大虚拟化特性的那5%~10%,从而引入如此巨大的运维成本是否值得
诚然,OpenStack实现了如此复杂的逻辑解耦,不存在任何单点模块,每个模块都是可以弹性伸缩扩容的,理论上可以管理成千上万的资源节点;但是,模块变多同时也意味着出问题的点变多,模块之间的通信又会引入可能的网络问题,我已经在想象将来的某天一台虚机突然莫名其妙的不能访问外网要如何去定位和解决
作为一个规模不大的测试团队,需要的虚机为100+的规模,这个虚拟化方案的运维负担有些过重了
最后,我并不确定OpenStack是否符合信创要求,于是我们将视线转向了其他方案
PVE
下一个备选方案就是PVE,oVirt,类ESXi的小型虚拟化方案,这类hypervisor以更加紧凑的方式实现了我们需要的所有功能,否定掉这类方案的原因也很简单粗暴,这类方案都需要在计算节点上运行一个较为强大的特殊操作系统或者engine,而我们的测试重点机器鲲鹏架构和openeluer不支持安装这样的管理端
基于上述调研的混合方案
从以上调研过程来看,我们已经因为运维成本问题放弃了OpenStack,因为兼容性问题放弃了PVE,最终形成了适用我们团队的可行方案
Webvirtmgr+Kvm+Lvm
LVM存储池的灵感来自于OpenStack和PVE,差别在于cinder会自动将本地lvm的volume通过iscsi协议映射到网络,从而提供VM跨机挂载,要提供这种程度的池化还需要有调度模块计算整体存储节点的capacity和装箱算法
而我们的物理机上都有多个硬盘(包括机械硬盘和SSD),对于虚机的池化需求来说是绰绰有余的,而LVM在本地提供了极为灵活的管理扩容和快照能力,作为Linux utility稳定性也足够
既然OpenStack和PVE都选择了LVM作为默认存储方案,那么它的性能应该也是能够满足需求的,至少会明显好于file-backed的qemu镜像webvirtmgr作为管理服务,功能上比PVE,oVirt之类的会弱很多,但是由于直接操作libvirtd,可以完全兼容不同的CPU和操作系统,只要kvm和qemu能安装就能管理,至少提供了集中式访问的方式
而运维操作可以通过Jenkins agent实现自动化需求,只要能够通过virsh命令行操作就可以创建为Jenkins pipeline可视化,底层还是依赖libvirtd,这也留下了较大的扩展空间
通过Linux bridge连接到物理网络给虚机分配量子机房IP,提供量子机房的物理网络直通
以上,兼容性,管理,运维成本,商业风险都得到了满足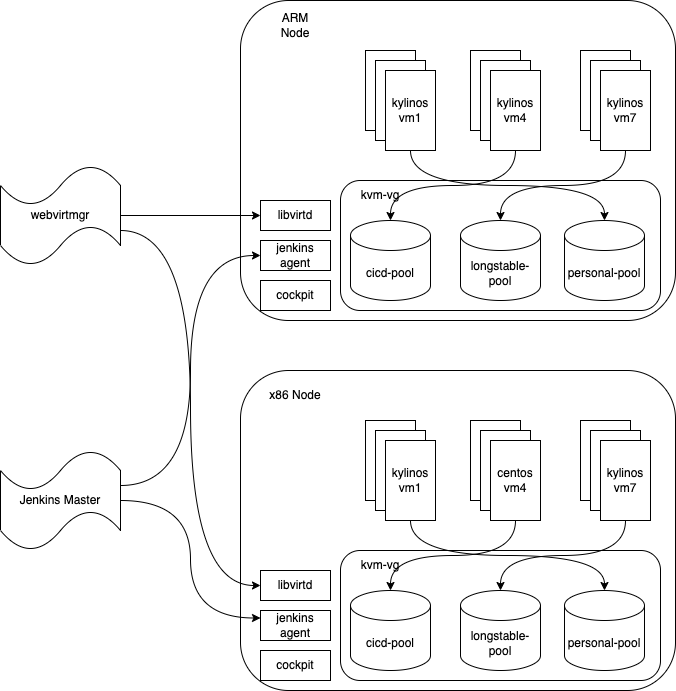
方案优势
- 兼容性好,即使以后加入新的平台也可以顺利纳入管理
- 稳定性好,本质上只依赖
kvm+qemu,以及lvm的稳定性 - 运维成本尚可,需要有更多的运维脚本和
Jenkins pipeline开发工作,可更好的定制化运维操作
方案劣势
- 当前管理功能较弱,需持续完善
- 部署依赖IT准备物理机的基础配置
将来计划
- VM creating pipeline
- VM ops pipeline
- admin wiki, principle, solution,arch, etc.
- IO performance optimize
- snapshot , backup, restore investigation
- more customized images
- kvm performance template
本文标题:作为测试架构师我如何选择团队的虚拟化方案
文章作者:xinlei
发布时间:2023-09-30
最后更新:2023-10-04
原始链接:https://clemenza.github.io/2023/09/30/why-i-spent-weeks-on-openstack-and-why-i-gave-it-up-at-last/
版权声明:The author owns the copyright, please indicate the source reproduced
